 Pristupačnost
Pristupačnost |
Jurica Kenda
|
|
|
Jurica Kenda
|
|
Today, buildings are becoming complex technical systems with great potential for energy savings through automation, networking and coordination of different subsystems. Implementing automation yields new possibilities for monitoring the operation of the system, which is crucial for informing users or detecting irregularities.
Unexpected user behavior in buildings is one of the key factors in creating a mismatch between the energy consumption model and the actual manifestation. Behavior as such is not necessarily possible to stop, but it is certainly desirable to raise the level of awareness about the problem and quantify its real consequences. Once obtained, the model makes it easier to predict, monitor and intervene in various aspects of energy consumption. Ultimately, these components provide the foundation for a building’s energy efficiency.
In this paper, the window openness classification model was obtained using heuristically guided data classification, parameterization, and ultimately machine learning.
The course of formalization of data processing (for extracting heuristics) was as follows:
1) Defining the seasonal context
2) Observation of seasonal context and remarks
3) Zoning to a time context
4) Analysis of frequent samples
5) Parameterization
6) Verification of the results
The knowledge obtained by visual inspection is translated into a parameterized form, suitable for inspection using an algorithm. The parameters obtained in this way served as parameters of the computational notation algorithm. Once tagged, the data was prepared for a machine learning algorithm.
As a machine learning algorithm, the Random Forest algorithm was chosen. The idea of this algorithm is as follows: by using a set of weak classifiers we get a strong classifier. The model of this algorithm is made up of decision trees. The decision tree is a conceptual structure in which, based on the characteristics of the data, a logical tree is built according to which the data moves during its classification.
The final model has the following efficiencies:
1) 1.0 for seasonal heating context
2) 0.79 for the seasonal cooling context
3) 0.99 for a transitional seasonal context
The average efficiency of the model is 0.92.
Although this result seems very promising at first glance, key aspects of the model should be considered. The model is trained on data whose knowledge is obtained by a heuristic algorithm. That knowledge is not in complete agreement with the real facts. The model as such in 92% of cases correctly answers the question of whether the window is open, but it must not be forgotten that the definition of window openness (from the perspective of the model) is not defined by the actual window opening but by a heuristically derived openness label. Thus, the model has no practical efficiency of 92%. This is one of the disadvantages of working with an incomplete data set. If the data on whether the window was open or not were known from the beginning of the work, the whole preparation of the data would be redundant, and the final efficiency of the model would be completely correct in practical terms.
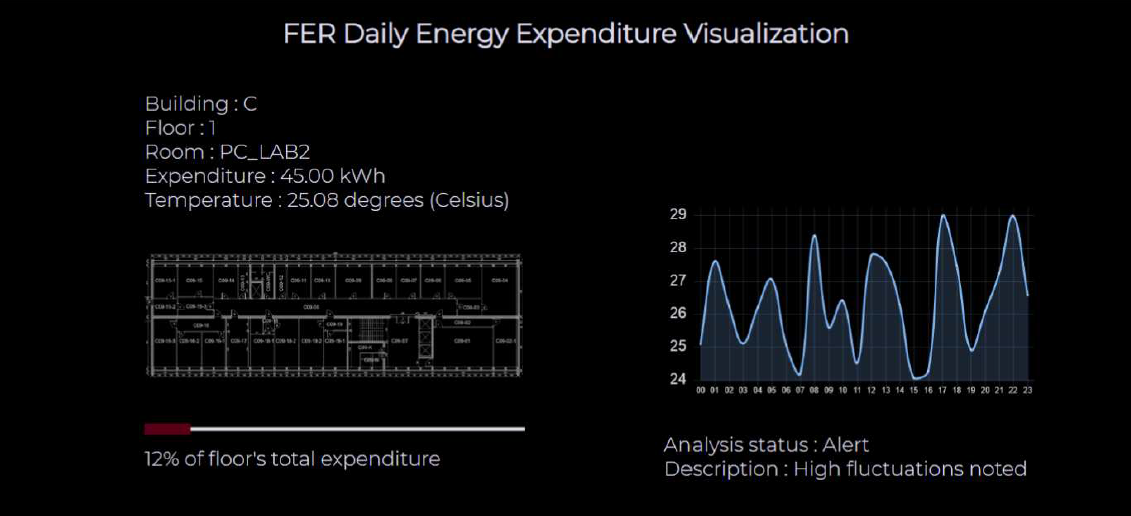
Visualization of data that is continuously collected can give a better insight into the behavior of the building and consumption in individual rooms. By correctly visualizing a large amount of data, it is possible to see certain anomalies and deviations from the expected values. Insight into such anomalies helps us to prevent them and additionally energetically optimize the observed building. For this reason, the web application FER Energy Expenditure Visualization (FER EEV) was created to complete this work.
Keywords: smart buildings, machine learning, window openness, decision trees, FER